
Proyectos de Software Grandes: Introducción al Monitoreo
Posted on October 25, 2025 • 6 minutes • 1135 words • Other languages: English
Este post es parte de mi serie de blogs sobre Proyectos de Software Grandes .
- Inspiración y Contexto
- ¿Por qué necesitamos instrumentación?
- ¿Cómo manejar todos estos backends de Telemetría?
- El Compromiso Arquitectónico: Pureza OTel vs. Simplicidad Pragmática
- ¿Qué sigue?
Inspiración y Contexto
Este post está inspirado en el video de YouTube de Aditya Singh - Codes , “Debug & Monitor Next.js Apps with Grafana Loki, Prometheus, Zipkin,” que nos da un blueprint moderno excelente para monitorear una aplicación Next.js.
Además, el thumbnail está inspirado en el video de YouTube “モニタリング” (Monitaringu, Monitoreo, que engancha con el tema de hoy) de DECO*27 .
Dichos los créditos, dejemos de adivinar qué está haciendo nuestro código y empecemos a saberlo.
¿Por qué necesitamos instrumentación?
Imaginate que te conectás a la daily del lunes, y te dicen que una ruta crítica en producción está rota. El único reporte que tienen es esta captura de pantalla aterradora:
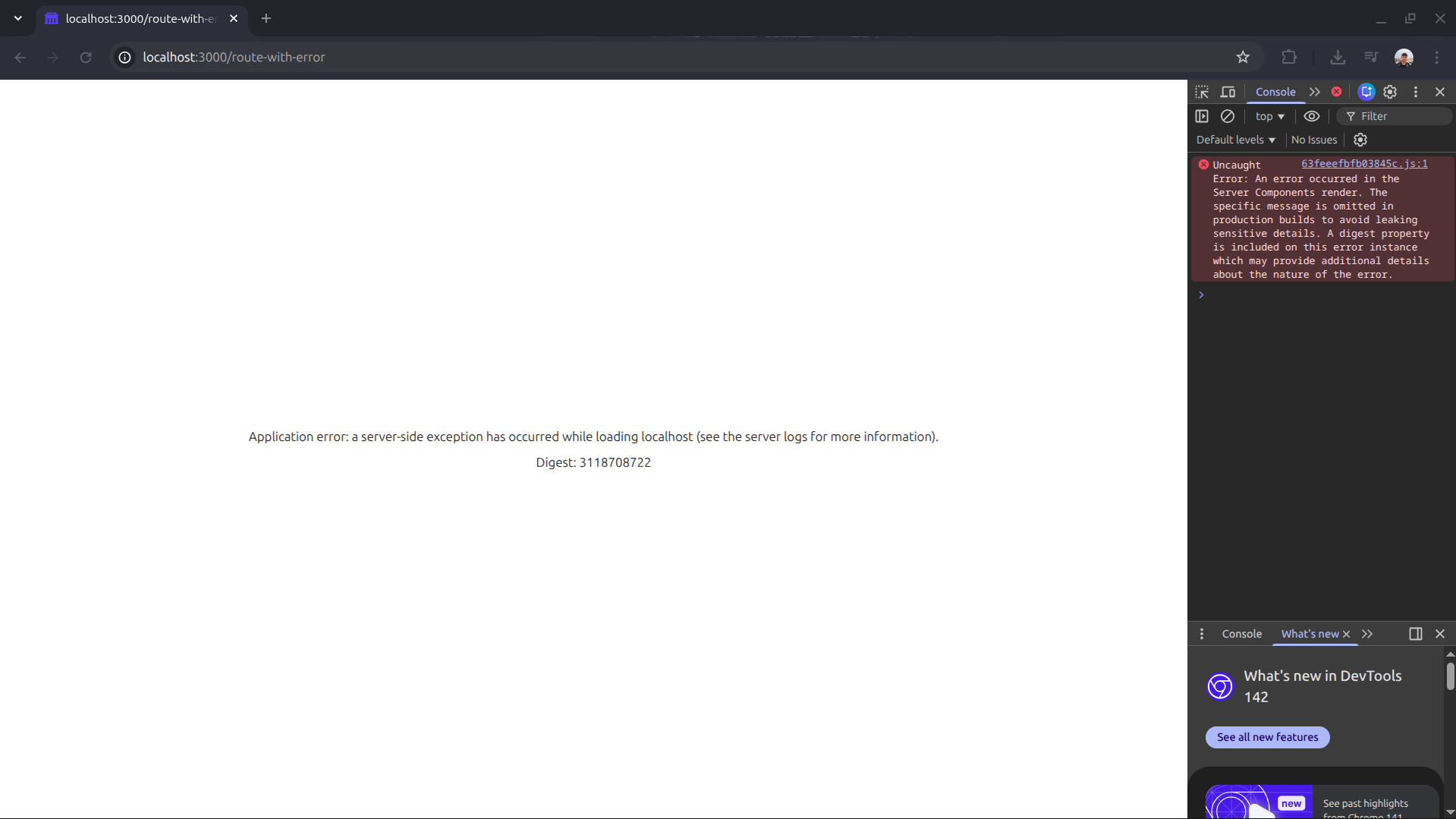
Este escenario levanta dos problemas inmediatos y gigantes para cualquier dev:
- Resolución Reactiva de Problemas: Solo te enterás de que hubo un problema cuando un usuario (o peor aún, un cliente) abre un ticket de soporte. Siempre estás jugando a la defensiva.
- Debugging a Ciegas: Sin un sistema de logging centralizado, intentar reproducir este bug basándote en una sola captura de pantalla en blanco es casi imposible. No tenés contexto, ni estado del servidor, ni el stack trace.
La solución para pasar de la adivinanza reactiva a la gestión proactiva es la Instrumentación. Este es el proceso de integrar código específico en tu aplicación para recolectar data operacional, dándote la visibilidad profunda necesaria para entender el rendimiento, la confiabilidad y el comportamiento del usuario.
Cómo funciona la Instrumentación
El proceso generalmente se divide en tres pasos lógicos:
- Recolección de Datos (La Aplicación): Modificamos nuestra aplicación Next.js para incluir código especializado que recolecta varios tipos de datos sobre el estado interno de la aplicación y el entorno del servidor host.
- Almacenamiento de Datos (Los Backends de Telemetría): La data recolectada se envía fuera del proceso de la aplicación a un backend de telemetría optimizado (una base de datos diseñada específicamente para logs, métricas o traces).
- Visualización (El Dashboard): Usamos una herramienta de visualización potente (como Grafana ) para extraer la data almacenada de los backends y presentarla en dashboards cohesivos y legibles.
Los Tres Pilares de la Data de Telemetría
La instrumentación se enfoca típicamente en recolectar tres tipos distintos de datos, conocidos como “Los Tres Pilares” de la observabilidad:
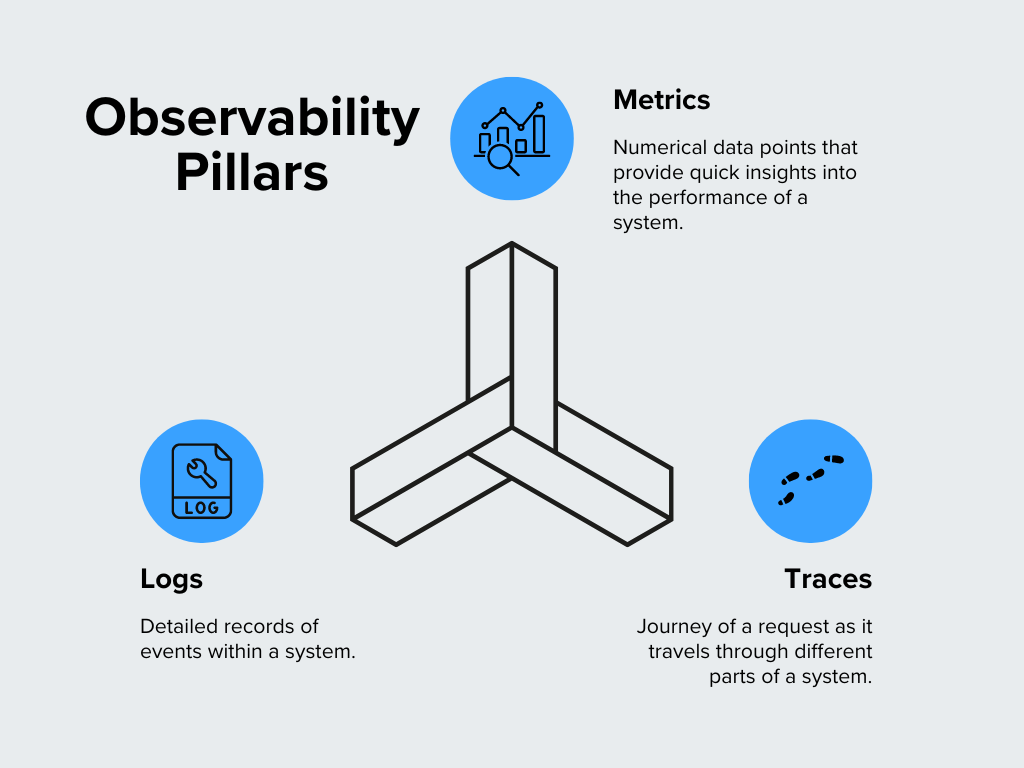
| Tipo de dato que se recolecta | Definición | Backend de Telemetría (dónde se guarda) |
|---|---|---|
| Logs | Registros de texto de eventos o estados específicos que suceden dentro de la aplicación. | Loki |
| Métricas | Puntos de datos numéricos y agregados (ej. uso de CPU, conteo de latencia de solicitudes, consumo de memoria). | Prometheus |
| Trazas | El viaje completo de una única solicitud mientras fluye a través de las diversas partes de tu sistema. | Tempo |
Usaremos las herramientas líderes de la industria listadas arriba. Si bien hay alternativas, esta combinación es robusta y popular.
¿Cómo manejar todos estos backends de Telemetría?
Cada vez que te encuentres en un escenario donde tenés un montón de servicios que necesitan comunicarse entre sí a través de una única red, deberías pensar inmediatamente en Docker y Docker Compose.
- Docker es una herramienta que te permite containerizar aplicaciones, asegurando que se ejecuten de la misma manera en cualquier lugar.
- Docker Compose es una herramienta de orquestación que nos permite definir y ejecutar aplicaciones Docker de múltiples contenedores.
En nuestro contexto de monitoreo, necesitamos que cinco servicios separados (Grafana, Loki, Prometheus, Tempo y OpenTelemetry Collector) se comuniquen entre sí a través de una única red. Docker Compose es el blueprint perfecto para definir este ecosistema de monitoreo de forma simple y reproducible.
En los próximos posts, vamos a abordar el archivo docker-compose.yml que define cómo se ve todo nuestro stack de monitoreo local.
El Compromiso Arquitectónico: Pureza OTel vs. Simplicidad Pragmática
Cuando se habla de observabilidad moderna, el OpenTelemetry (OTel) Collector es muchas veces aclamado como la respuesta universal. Simplifica arquitecturas grandes al proporcionar un pipeline potente y centralizado para toda la data de telemetría.
La Arquitectura Recomendada por la Industria (Centrada en OTel):
Idealmente, cada señal de datos (logs, métricas y traces) pasaría de la Aplicación al OTel Collector , que luego las procesaría y las dirigiría al backend apropiado.
- Punto Único de Integración: Tu aplicación solo necesita conectarse a un endpoint OTLP.
- Desacoplamiento: Tu código de aplicación no necesita saber los detalles específicos de Prometheus o Loki.
- Flexibilidad y Procesamiento: El collector maneja el sampling, batching, transformación y balanceo de carga.
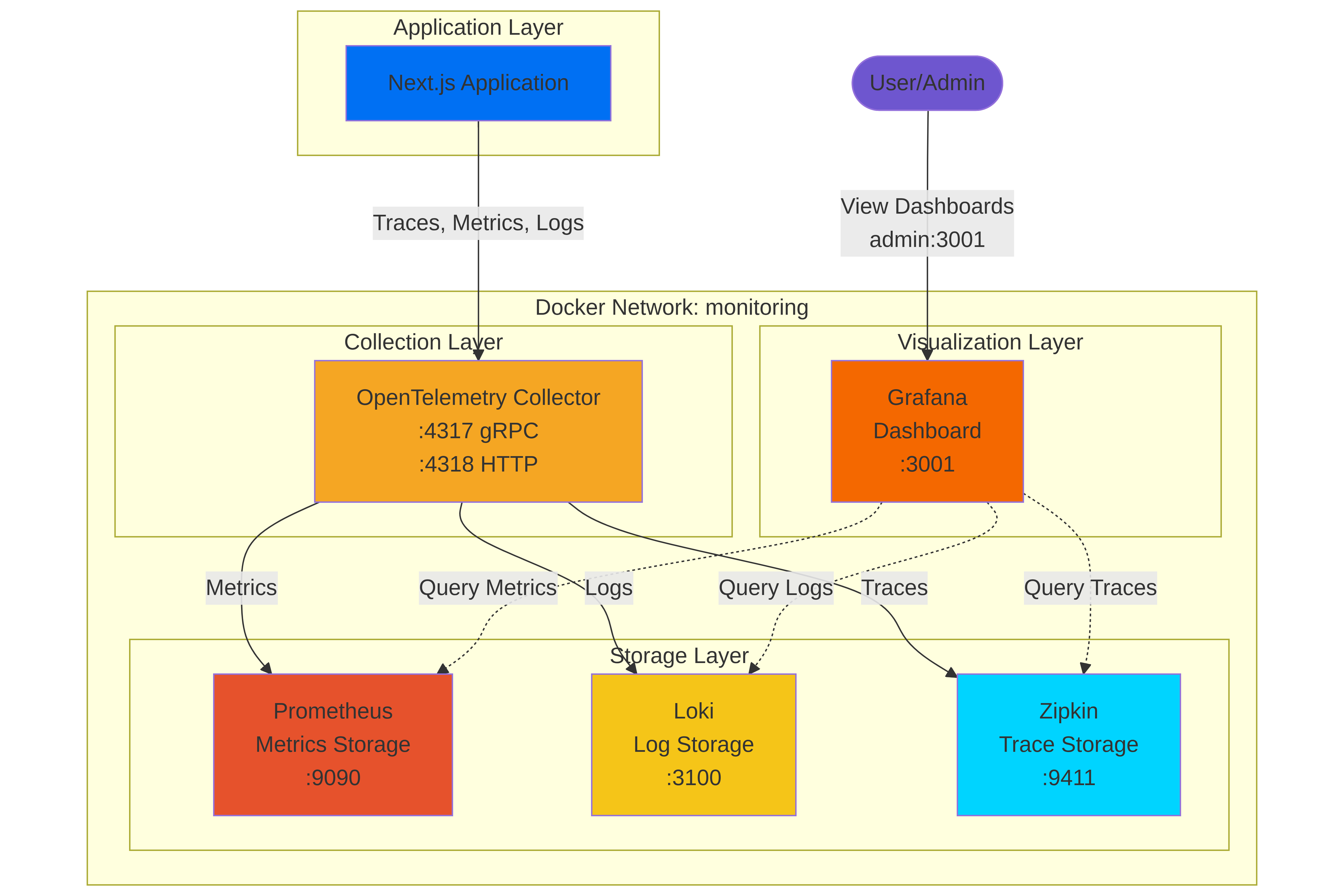
Sin embargo, como desarrollador con experiencia, aprendí que la arquitectura ideal a menudo sacrifica la simplicidad y la mantenibilidad en favor de la pureza filosófica.
Después de batallar para replicar esta configuración exacta centrada en OTel para la aplicación Node de Next.js, me encontré con dos obstáculos pragmáticos que justificaron simplificar el plan:
- Madurez OTLP de Loki: Aunque el soporte OTLP en Loki está mejorando, configurar el receiver OTLP para logs resultó engorroso comparado con las librerías de transporte dedicadas ya existentes.
- Solución Pragmática: Vamos a saltear OTel para logs y usar una librería probada y directa: pino-loki .
- Recolección de Métricas de Prometheus: El NodeSDK oficial de OTel no recolecta automáticamente algunas métricas clave del runtime de Node.js (como el uso de CPU, el tamaño del heap y la información específica de la versión) requeridas por los dashboards estándar de Grafana Prometheus.
- Solución Pragmática: Pelear con el JSON de un dashboard custom o cazar librerías OTel compatibles es una trampa de tiempo. El camino más simple es usar la librería estándar de la industria para Node.js Prometheus: prom-client , que exporta todas estas métricas automáticamente a través de un endpoint HTTP estándar que Prometheus puede scrapear fácilmente.
Por lo tanto, nuestra Arquitectura Práctica elegida utilizará un enfoque híbrido que se apoya en herramientas sencillas y establecidas donde la integración OTel es compleja, reservando el OTel Collector para lo que mejor hace: las trazas.
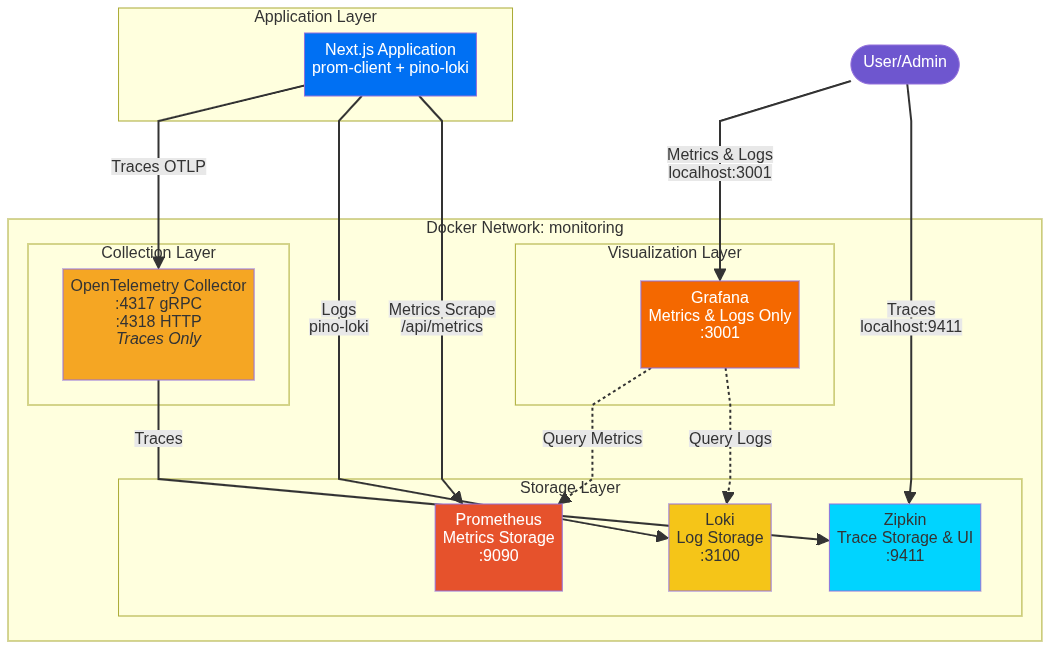
| Componente | Ideal de la Industria (OTel Puro) | Enfoque Práctico (Híbrido) | Justificación |
|---|---|---|---|
| OTEL Collector | Maneja todas las señales | Solo Trazas | Enfoque en un manejo de traces fácil y confiable. |
| Logs | App → OTel → Loki | App → Directo (pino-loki) → Loki | Configuración más simple, soporte superior de la librería. |
| Métricas | App → OTel → Prometheus | Prometheus ← Scrapea /api/metrics ← NextJS | Aprovecha prom-client para métricas automáticas del runtime. |
Este modelo híbrido nos da observabilidad completa con máxima simplicidad.
¿Qué sigue?
En el próximo post, vamos a empezar a codear, escribiendo el boilerplate fundacional para inicializar los pilares de monitoreo y preparar nuestro panel de control de “vista única”: trazas junto con métricas y registros dentro de Grafana.
Próximo Post: Proyectos de Software Grandes: Panel de Control de Monitoreo